 | AccessLog | サンプルソース |
|---|---|---|
Webサーバーが残すログを正規表現で解析して、検索エンジンGoogleのクローラーであるGooglebotからのアクセスを抽出します。Googleがきちんと『愛のJava256本ノック』を収集してるかチェックしてやる! |
AccessLog.java |
/**
* 愛のJava256本ノック for Java 5.0
* Javaサンプルソース ver0.2C "AccessLog"
* AccessLog.java 「正規表現を使いアクセスログからGooglebotのアクセスを検出する」
*
* 2005/09/23 制作:安永ノリカズ
*
* 【コンパイル&実行方法】
* >javac AccessLog.java
* >java AccessLog
* 【キーワード】
* 正規表現(regular expression), Googlebot, クローラー(crawler),
* HTTPステータスコード(status code)
*
* 【試してみよう】
* Googlebot以外のロボットのアクセスを検出する。
* 外部リンク(www.groovy-number.com以外)から参照されたアクセスを検出する。
*/
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.lang.String;
import java.lang.System;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class AccessLog {
public static void main(String[] A00) {
String L00 = "access_log.txt";
try {
BufferedReader L01 = new BufferedReader(new FileReader(L00));
Pattern L02 = Pattern.compile(".+ .+ .+ \\[(.+)\\] \"(.+)\" .+ .+ \".+\" \"(.+)\"");
String L03;
while( (L03 = L01.readLine()) != null ) {
Matcher L04 = L02.matcher(L03);
if (L04.matches()) {
if (L04.group(3).contains("Googlebot")) {
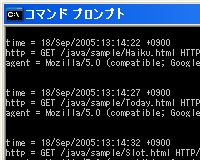
System.out.println("time = " + L04.group(1));
System.out.println("http = " + L04.group(2));
System.out.println("agent = " + L04.group(3));
System.out.println();
}
} else {
System.out.println("解析できない行がありました:" + L03);
}
}
L01.close();
} catch(IOException L05) {
System.out.println(L00 + "を読み込み中に例外が発生しました。");
}
}
}
/* ■ クラスの外でちょっと一言 ■
Webサーバーのアクセスログには、いつ、どのような形でページがアクセスされ
たのか、その記録が残っています。誰かがページを閲覧した場合以外にも、検索
エンジンが行うページの自動収集の記録などもログに残ります。
Googleはページの収集にGooglebotというクローラー(ロボットやスパイダーと
も呼ばれる)を使用しており、アクセスログにおいては、ブラウザーの名前が残
る部分に"Googlebot"という文字を含んだ名前を残します。今回はそのデータの
みを抽出してみました。
このサンプルを読み解く前に、付属のaccess_log.txtを開いて、アクセスログが
どんなものかを確認しておいてください。ログの形式はスペース区切りで、「ホ
スト名 識別情報 認証ユーザー 日時 リクエスト ステータス 送信バイト数 参
照元 ブラウザー名」となってます。
正規表現の中にに"()"がありますが、これはパターンをマッチさせた後、その部
分を抜き出すためのものです。例えば、Matcherのgroup(3)というメソッドは「3
番目の()」つまりブラウザー名を取得することになります。
*/